maldoc in PDFで遊ぶ
要約
この記事は所属組織の勉強会で発表した内容のコピーです。
内容は以下のとおりです。
- maldoc in PDFが気になったので色々調べてみる。
- maldoc in PDFをWordでもPDFビューアーでも開けるようにするための検証をする。
- 検証結果を元に両刀のファイルを作成する。
maldoc in PDFとは
2023/8/22にJPCERT/CCが発表した、PDFファイル内に悪性のWordファイルを埋め込む方法のことです。
JPCERT/CCが報告した元記事はコチラです。
一見ファイルタイプがPDFのように見えますが、JPCERT/CCの報告では拡張子がdocになっており、Wordで開くとVBAで悪性のコマンドが実行されてしまうというものです。
解析してみる
予め無害化しておいた検体を解析していきます。
ファイルタイプ
報告通り、ファイルタイプはPDFファイルとして認識されています。
マジックバイトもPDFのそれと一致していることがわかります。
主要なビューアーで開いてみる
主要なビューアーで開いてみましたがPDFとしては破損しているようで正常に開けたビューアーはありませんでした。
Adobe Acrobat Readerの場合
PDF XChange Viewerの場合
スクショ取り忘れましたが、Chromeなどのブラウザでも正常に開くことはできませんでした。
なぜPDFとして開けないのか
ファイルタイプはPDFとして認識されているのになぜビューアーで開くことができないのかを追加調査しました。
まず、PDFの構造について大雑把に理解した結果、下記のようになっていることがわかりました。
この内、トレイラーの末尾(ファイル末尾)には%%EOFというシグネチャが出現します。(LFは有っても無くてもいいっぽい)
下記は有効なPDFの末尾を表示した結果です。末尾に%%EOFが出現しています。
対して検体の末尾には%%EOFが確認できませんでした。
それどころか検体には前述のトレイラーセクション自体が確認できませんでした。
有効なPDF
検体
以上のことから、maldoc in PDFはPDF部分の末尾が、PDFとして有効でないためPDFビューアーでは開けない、と推測しました。
JPCERT/CCの記事では拡張子が「doc」になっていたようなのでPDFファイルとして開けるようにはしてないのでしょうか?(docとして認識されるのが回避できればいいから)
この時点で私のモチベーションがWordでもPDFビューアーでも開けるmaldoc in PDFを作るになりました。
とはいえもう少し調べる必要があるので解析を継続します。
ファイル抽出
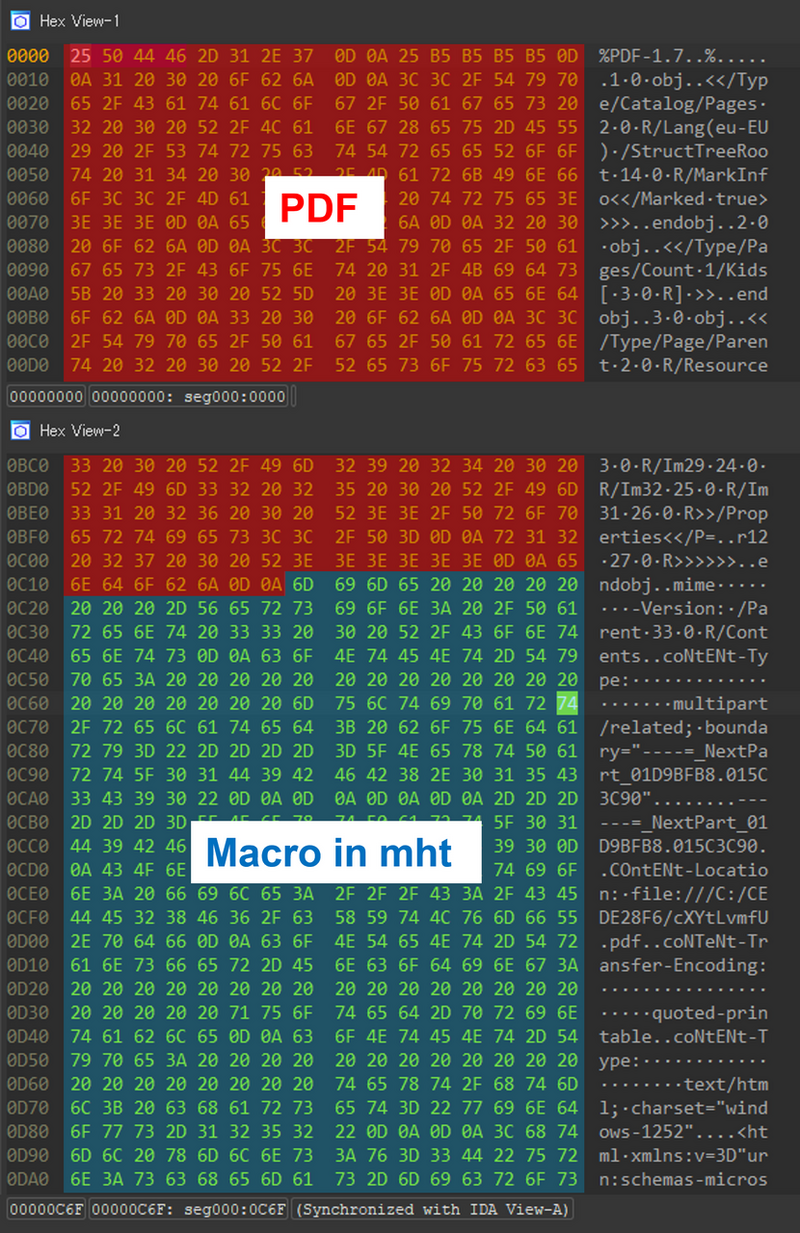
maldoc in PDFはPDFファイルの後ろにMHTMLという形式のファイルがくっついている感じになっています。
検体を確認すると、MHTMLファイル部分が0x239から開始されていることがわかります。
(MTHMLファイルはMime-Version:というヘッダから始まるようです。)
MHTML部分はファイル末尾まで続いていたため、ddコマンドで0x239からファイル末尾を別ファイルとして保存します。
抽出されたファイルはHTML形式として認識されているようです。
抽出されたファイルを確認すると、ファイル先頭にPDFに現れる文字列が出現していたり、スペースや大文字小文字が入り混じっているのが特徴的です。
このHTML要素のうち、「」はマクロのエンコードに使用されるActiveMimeというファイル形式を指すということがわかりました。
そして、そのhref属性に参照先が載ってくるとのこと。
href属性をURLデコードすると「lonhzFH_files/image7891805.jpg」になります。
そしてMHTMLファイル内で「lonhzFH_files/image7891805.jpg」を文字列検索すると、以下の部分がヒットします。
Content-Transfer-Encodingからこの文字列は難読化されたBase64文字列だということがわかりますので、まずこの部分をファイルとして抽出します。
スペースやLFでパディングされていたので削除して難読化を解除します。
その後、Base64デコードするとActiveMimeというシグネチャが出現します。このデータをファイルとして保存しておきます。
ActiveMime形式について色々調べていると、この形式はoffset 0x32にzlibが出現するということがわかりました。
バイナリを確認してもそのようになっています。
ということでzlib部分を抽出してdecompressします。
decompressしたファイルのマジックバイトを確認すると、旧OfficeのOLE2フォーマットだということがわかります。
OLE2フォーマットということがわかったのでoletoolsが使用できます。
ここまでで、OLE2フォーマットが埋め込まれていることはわかりましたが、新しい疑問が出てきます。
なぜファイル先頭にPDFが存在するのにWordで開けるのか
WordはMHTMLファイルの先頭部にPDFが存在するのに、なぜ正常にMHTMLファイルを開けるのか、が疑問です。
Twitterでは下記のようなコメントもあったため、Wordの挙動を検証してみます。
まず、適当なWordファイルを作成します。
ファイルをMHTML形式として保存します。
保存したMTHMLファイルは検体のMTHML部分と似たような構造になっていることが確認できます。(当然ですが。)
保存したMTHMLファイルはもちろんWordで開くことができます。
検証のため、このファイルの先頭にゴミ文字列を入れてみます。
依然Wordで開くことができました!
ファイル先頭にゴミ文字列があっても正常に開ける、となると次に気になるのは何バイトまでゴミ文字列を挿入できるかというところです。
この疑問を検証してみたところ、どうやら4082バイトまでは挿入できるようでした。
OK
NG
4082バイトを超える文字列を挿入すると下記のように、MHTML部分がそのまま文字列として表示されてしまう状態になりました。
なぜ、4082バイトという中途半端な数字なのか辻褄を合わせてみたところ、4082+len("MIME-Version: ")でちょうど4096バイトになることがわかりました。
この辺の仕様については詳細に述べられている資料が見つからなかったのであくまで推測ですが、ファイル先頭から4095バイト以内にMIME-Version:が出現する、
またはファイル先頭から4096バイト以内にMIME-Version: (スペース含む)が出現するMHTMLファイルはWordが開けるのではないでしょうか。
この推測が正しいとするとMHTMLファイルの先頭に埋め込めるPDFデータは4080バイト以内であればOKということになります。
PDFビューアーはPDFファイルの後ろにゴミデータがあっても開けるのか
次にPDFとして開くための検証です。
maldoc in PDFはPDFの後ろにMHTMLが存在します。
したがって、PDFビューアーが%%EOFの後ろにゴミ文字列があった場合にどのような挙動をとるか検証を行います。
適当なPDFファイルの末尾に適当な文字列を追加して見ます。
この状態でPDFビューアーで開いてみても正常に開けることが確認できます。
検証では4096バイトを追記しましたが、10MB書き込んでも正常に開けることを確認しています。
このことからPDFビューアーはファイル末尾にゴミ文字列があろうと%%EOFからパースを始めるんだろうということが推測できました。
そのため、maldoc in PDFのMHTML部分はある程度自由にコンテンツを作成することができそうです。
maldoc in PDF 作成
ExcelやWordから作成したPDFは4080バイトを余裕で超えてしまうので、検体からPDF部分のデータを拝借します。
表示される文字列部分はそれっぽい文章に編集しました。
続いて組み合わせるMHTMLファイルを作成します。
VBAを実行させるのでまず適当なマクロを記述してからMHTMLファイルとして保存します。
PDFとMHTMLを結合して保存します。
結果
保存したファイルの拡張子をPDFとして開くとPDF部分に定義した文字列が表示されます。
また、拡張子をdocにして開くとVBAが実行され電卓が起動されます。
この動画ですとマクロを有効化にするダイアログが出ていませんが通常はそのダイアログの有効化するを選択しないとマクロは実行されないはずです。
今回は事前に有効化してしまっていたので表示されていません。
まとめ
- PDFビューアーは
%%EOFの後ろにゴミ文字列があろうが関係なく開ける。 - MHTMLファイルはファイル先頭に4080バイト以内のゴミ文字列があってもWordで開ける。
- PDFファイル部分を4080バイト以内に収めればPDFビューアーでもWordでも開けるファイルが作成できる。